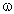 (omega).
(omega).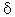 *Impactt-1 (delta) and (omega). As long as the parameter is greater than 0 and less than 1 (the bounds of system stability), the initial abrupt impact will gradually decay. If is near 0 (zero) than the decay will be very quick, and the impact will have entirely disappeared after only a few observations. If is close to 1 then the decay will be slow, and the intervention will affect the series over many observations. Note that, when evaluating a fitted model, it is again important that both parameters are statistically significant; otherwise one could reach paradoxical conclusions. For example, suppose the parameter is not statistically significant from 0 (zero) but the parameter is; this would mean that an intervention did not cause an initial abrupt change, which then showed significant decay.
*Impactt-1 (delta) and (omega). As long as the parameter is greater than 0 and less than 1 (the bounds of system stability), the initial abrupt impact will gradually decay. If is near 0 (zero) than the decay will be very quick, and the impact will have entirely disappeared after only a few observations. If is close to 1 then the decay will be slow, and the intervention will affect the series over many observations. Note that, when evaluating a fitted model, it is again important that both parameters are statistically significant; otherwise one could reach paradoxical conclusions. For example, suppose the parameter is not statistically significant from 0 (zero) but the parameter is; this would mean that an intervention did not cause an initial abrupt change, which then showed significant decay.
Abrupt Permanent Impact.
In Time Series, a permanent abrupt impact pattern simply implies that the overall mean of the times series shifted after the intervention; the overall shift is denoted by (omega).
Accept-Support (AS) Testing. In this type of statistical test, the statistical null hypothesis is the hypothesis which, if true, supports the experimenter's theoretical hypothesis. Consequently, in AS testing, the experimenter would prefer not to obtain "statistical significance."
In AS testing, accepting the null hypothesis supports the experimenter's theoretical hypothesis.
For more information see the chapter on Power Analysis.
Activation Function (in Neural Networks). A function used to transform the activation level of a unit (neuron) into an output signal. Typically, activation functions have a "squashing" effect. Together with the PSP function (which is applied first) this defines the unit type.
Additive Season, Damped Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" both by a damped trend component (independently smoothed with the single parameter 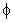 , this model is an extension of Brown's one-parameter linear model, see Gardner, 1985, p. 12-13) and an additive seasonal component (smoothed with parameter ). For example, suppose we wanted to forecast from month to month the number of households that purchase a particular consumer electronics device (e.g., VCR). Every year, the number of households that purchase a VCR will increase, however, this trend will be damped (i.e., the upward trend will slowly disappear) over time as the market becomes saturated. In addition, there will be a seasonal component, reflecting the seasonal changes in consumer demand for VCR's from month to month (demand will likely be smaller in the summer and greater during the December holidays). This seasonal component may be additive, for example, a relatively stable number of additional households may purchase VCR's during the December holiday season. To compute the smoothed values for the first season, initial values for the seasonal components are necessary. Also, to compute the smoothed value (forecast) for the first observation in the series, both estimates of S0 and T0 (initial trend) are necessary. By default, these values are computed as:
, this model is an extension of Brown's one-parameter linear model, see Gardner, 1985, p. 12-13) and an additive seasonal component (smoothed with parameter ). For example, suppose we wanted to forecast from month to month the number of households that purchase a particular consumer electronics device (e.g., VCR). Every year, the number of households that purchase a VCR will increase, however, this trend will be damped (i.e., the upward trend will slowly disappear) over time as the market becomes saturated. In addition, there will be a seasonal component, reflecting the seasonal changes in consumer demand for VCR's from month to month (demand will likely be smaller in the summer and greater during the December holidays). This seasonal component may be additive, for example, a relatively stable number of additional households may purchase VCR's during the December holiday season. To compute the smoothed values for the first season, initial values for the seasonal components are necessary. Also, to compute the smoothed value (forecast) for the first observation in the series, both estimates of S0 and T0 (initial trend) are necessary. By default, these values are computed as:
T0 = (1/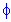 )*(Mk-M1)/[(k-1)*p]
)*(Mk-M1)/[(k-1)*p]
where
is the smoothing parameter
k is the number of complete seasonal cycles
Mk is the mean for the last seasonal cycle
M1 is the mean for the first seasonal cycle
p is the length of the seasonal cycle
and S0 = M1 - p*T0/2
Additive Season, Exponential Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" both by an exponential trend component (independently smoothed with parameter 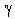 ) and an additive seasonal component (smoothed with parameter ). For example, suppose we wanted to forecast the monthly revenue for a resort area. Every year, revenue may increase by a certain percentage or factor, resulting in an exponential trend in overall revenue. In addition, there could be an additive seasonal component, for example a particular fixed (and slowly changing) amount of added revenue during the December holidays.
) and an additive seasonal component (smoothed with parameter ). For example, suppose we wanted to forecast the monthly revenue for a resort area. Every year, revenue may increase by a certain percentage or factor, resulting in an exponential trend in overall revenue. In addition, there could be an additive seasonal component, for example a particular fixed (and slowly changing) amount of added revenue during the December holidays.
T0 = exp((log(Mk) - log(M1))/p)
where
k is the number of complete seasonal cycles
Mk is the mean for the last seasonal cycle
M1 is the mean for the first seasonal cycle
p is the length of the seasonal cycle
and S0 = exp(log(M1) - p*log(T0)/2)
Additive Season, Linear Trend.
In this Time Series model, the simple exponential smoothing forecasts are "enhanced" both by a linear trend component (independently smoothed with parameter ) and an additive seasonal component (smoothed with parameter ). For example, suppose we were to predict the monthly budget for snow-removal in a community. There may be a trend component (as the community grows, there is a steady upward trend for the cost of snow removal from year to year). At the same time, there is obviously a seasonal component, reflecting the differential likelihood of snow during different months of the year. This seasonal component could be additive, meaning that a particular fixed additional amount of money is necessary during the winter months, or (see below) multiplicative, that is, given the respective budget figure, it may increase by a factor of, for example, 1.4 during particular winter months.
T0 = (Mk-M1)/((k-1)*p
where
k is the number of complete seasonal cycles
Mk is the mean for the last seasonal cycle
M1 is the mean for the first seasonal cycle
p is the length of the seasonal cycle
and S0 = M1 - T0/2
Additive Season, No Trend.
This Time Series model is partially equivalent to the simple exponential smoothing model; however, in addition, each forecast is "enhanced" by an additive seasonal component that is smoothed independently (see The seasonal smoothing parameter ). This model would, for example, be adequate when computing forecasts for monthly expected amount of rain. The amount of rain will be stable from year to year, or change only slowly. At the same time, there will be seasonal changes ("rainy seasons"), which again may change slowly from year to year.
Adjusted means. These are the means that one would get after removing all differences that can be accounted for by the covariate in an analysis of variance design (see ANOVA).
AID. AID (Automatic Interaction Detection) is a classification program developed by Morgan & Sonquist (1963) that led to the development of the THAID (Morgan & Messenger, 1973) and CHAID (Kass, 1980) classification tree programs. These programs perform multi-level splits when computing classification trees. For discussion of the differences of AID from other classification tree programs, see A Brief Comparison of Classification Tree Programs.
Algorithm. As opposed to heuristics (which contain general recommendations based on statistical evidence or theoretical reasoning), algorithms are completely defined, finite sets of steps, operations, or procedures that will produce a particular outcome. For example, with a few exceptions, all computer programs, mathematical formulas, and (ideally) medical and food recipes are algorithms.
See also, Data Mining, Neural Networks, heuristic.
Anderson-Darling Test. The Anderson-Darling procedure is a general test to compare the fit of an observed cumulative distribution function to an expected cumulative distribution function. This test is applicable to complete data sets (without censored observations). The critical values for the Anderson-Darling statistic have been tabulated (see, for example, Dodson, 1994, Table 4.4) for sample sizes between 10 and 40; this test is not computed for n less than 10 and greater than 40.
The Anderson-Darling test is used in Weibull and Reliability/Failure Time Analysis; see also, Mann-Scheuer-Fertig Test and Hollander-Proschan Test.
Append a network. A function to allow two neural networks (with compatible output and input layers) to be joined into a single network.
Append Cases and/or Variables. Functions that add new cases (i.e., rows of data) and/or variables (i.e., columns of data) to the end of the data set (the "bottom" or the right hand side, respectively). Cases and Variables can also be inserted in arbitrary locations of the data set.
Application Programming Interface (API). Application Programming Interface is a set of functions that conform to conventions of a particular operating system (e.g., Windows) which allows the user to programmatically access the functionality of another program. For example, the kernel of STATISTICA Neural Networks can by accessed by other programs packages (e.g., Visual Basic, STATISTICA BASIC, Delphi, C, C++) in a variety of ways.
Arrow. An element in a path diagram used to indicate causal flow from one variable to another, or, in narrower interpretation, to show which of two variables in a linear equation is the independent variable and which is the dependent variable.
Assignable Causes and Actions. In the context of monitoring quality characteristics you have to distinguish between two different types of variability: Common cause variation describes random variability that is inherent in the process and affects all individual values. Ideally, when your process is in-control, only common cause variation will be present. In a quality control chart, it will show up as a random fluctuation of the individual samples around the center line with all samples falling between the upper and lower control limit and no non-random patterns (runs) of adjacent samples. Special cause or assignable cause variation is due to specific circumstances that can be accounted for. It will usually show up in the QC chart as outlier samples (i.e., exceeding the lower or upper control limit) or as a systematic pattern (run) of adjacent samples. It will also affect the calculation of the chart specifications (center line and control limits).
With some software programs, if you investigate the out-of-control conditions and you find an explanation for them, you can assign descriptive labels to those out-of-control samples and explain the causes (e.g., valve defect) and actions that have been taken (e.g. valve fixed). Having causes and actions displayed in the chart will document that the center line and the control limits of the chart are affected by special cause variation in the process.
Asymmetrical Distribution. If you split the distribution in half at its mean (or median), then the distribution of values on the two sides of this central point would not be the same (i.e., not symmetrical) and the distribution would be considered "skewed."
See also, Descriptive Statistics Overview.
Attribute (attribute variable). An alternative name for a nominal variable.
Augmented Product Moment Matrix. For a set of p variables, this is a (p + 1) X (p + 1) square matrix. The first p rows and columns contain the matrix of moments about zero, while the last row and column contain the sample means for the p variables. The matrix is therefore of the form:
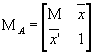
where M is a matrix with element
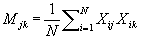
and 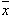 is a vector with the means of the variables (see Structural Equation Modeling).
is a vector with the means of the variables (see Structural Equation Modeling).
Autoassociative Network. A neural network (usually a multilayer perceptron) designed to reproduce its inputs at its outputs, while "squeezing" the data through a lower-dimensionality middle layer. Used for compression or dimensionality reduction purposes (see Fausett, 1994; Bishop, 1995).
Automatic Network Designer.
An heuristic algorithm (implemented in STATISTICA Neural Networks) which experimentally determines an appropriate network architecture to fit a specified data set.
